A Shared Task on Understanding Figurative Language
Tuhin Chakrabarty, Arkadiy Saakyan, Debanjan Ghosh, Smaranda Muresan

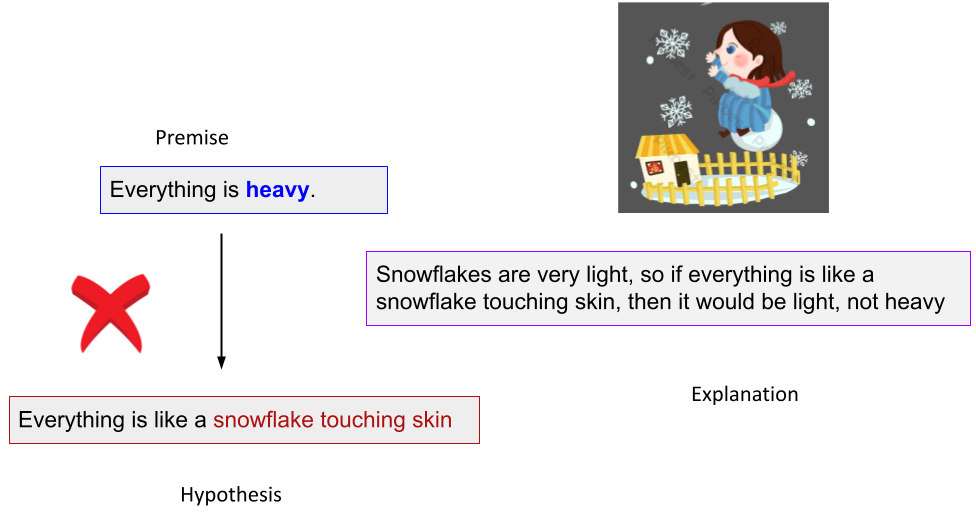
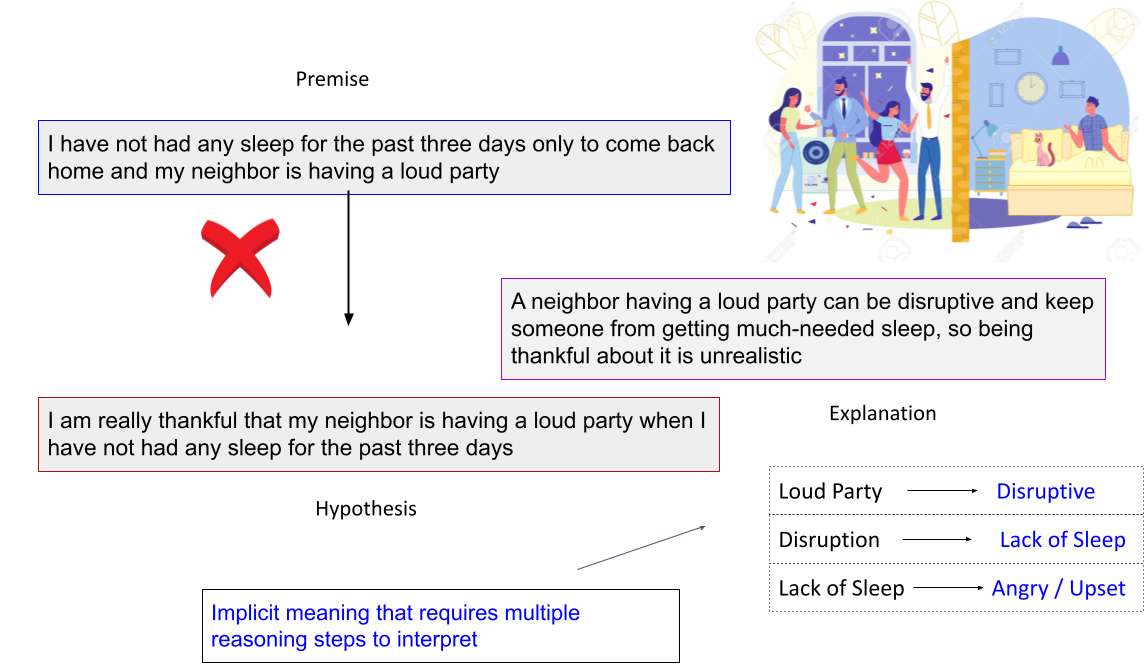
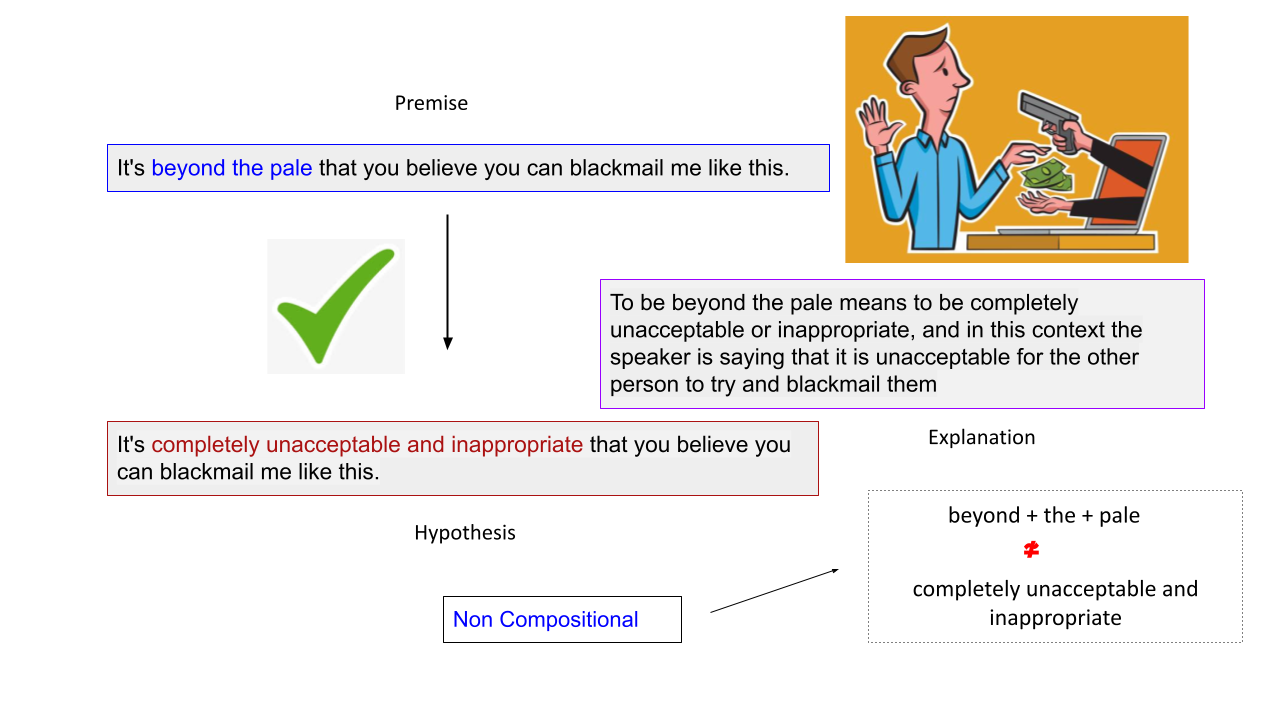
Our data contains 9,000 high-quality literal, figurative sentence pairs with entail/contradict labels and the associated explanations. The benchmark spans four types of figurative language: Sarcasm, Simile, Metaphor, and Idiom.
A noteworthy property of our data is that both the entailment/contradiction labels and the explanations are w.r.t the figurative language expression (i.e., metaphor, simile, idiom) rather than other parts of the sentence.
Our data is challenging because it inherently requires 1) relational reasoning using background commonsense knowledge, and 2) finegrained understanding of figurative language. Our dataset is constructed through a combination of few-shot prompting with GPT3 and crowd-sourcing from AMT followed by experts judging and minimally editing GPT-3 output to ensure quality control.